Trong kỷ nguyên số, việc quản lý và trích xuất thông tin từ các tài liệu điện tử là một thách thức lớn. Đặc biệt, các tài liệu PDF bằng tiếng Việt với cấu trúc phức tạp, chất lượng hình ảnh không đồng đều và đặc trưng ngôn ngữ riêng biệt luôn là một “bài toán khó” đối với các hệ thống truyền thống. Việc này gây mất thời gian, tốn kém chi phí và thường xuyên dẫn đến sai sót.

Xuất phát từ nhu cầu đó, học viên Trần Hữu Song Tùng – lớp DT2210L (chuyên ngành Khoa học Dữ liệu & Trí tuệ Nhân tạo) đã phát triển đồ án “Text Extraction from PDF Documents using Vision-Language Models”. Đây là một đồ án không chỉ giải quyết triệt để những vấn đề trên mà còn mở ra một hướng đi mới đầy tiềm năng cho việc xử lý văn bản tiếng Việt.
Phân tích bài toán cốt lõi và lời giải đột phá
Trước đây, việc trích xuất thông tin từ các tài liệu scan thường dựa vào công nghệ OCR (Optical Character Recognition) truyền thống. Tuy nhiên, những hệ thống này chỉ có khả năng nhận diện ký tự đơn lẻ và gần như “bất lực” trước các tài liệu có bố cục phức tạp, bao gồm cả bảng biểu, con dấu, chữ ký hay những lỗi nhỏ trong dấu tiếng Việt.

Đồ án này đã giải quyết vấn đề bằng cách áp dụng Vision-Language Models (VLM). Khác với OCR chỉ “đọc” chữ, VLM có khả năng “nhìn” và “hiểu” toàn bộ ngữ cảnh, bố cục của trang tài liệu. Điều này cho phép hệ thống nhận biết các mối quan hệ không gian giữa văn bản và hình ảnh, từ đó trích xuất thông tin một cách chính xác và có ngữ cảnh hơn hẳn.
Tính năng đột phá nâng tầm hiệu quả xử lý
Dự án này nổi bật với hàng loạt các tính năng được thiết kế để giải quyết những thách thức lớn nhất trong việc trích xuất văn bản:
- Hiểu cấu trúc tài liệu: Hệ thống có khả năng phân tích và nhận diện các yếu tố cấu trúc như tiêu đề, đoạn văn, danh sách và bảng biểu. Điều này đảm bảo dữ liệu trích xuất được sắp xếp một cách logic và có trật tự.
- Xử lý các yếu tố phức tạp: Đồ án đã tích hợp các cơ chế để xử lý hiệu quả những yếu tố phi văn bản như con dấu, chữ ký hay hình ảnh, giúp mô hình không bị nhầm lẫn và duy trì độ chính xác cao.
- Trích xuất dữ liệu theo ngữ cảnh: VLM không chỉ nhận dạng từ mà còn hiểu được ý nghĩa của chúng dựa trên bối cảnh xung quanh. Tính năng này giúp trích xuất các trường thông tin cụ thể (ví dụ: họ tên, địa chỉ, ngày tháng) một cách chính xác theo cấu trúc yêu cầu cần trích xuất thông tin.
- Khả năng thích ứng cao: Hệ thống được thiết kế để xử lý các tài liệu có chất lượng hình ảnh không đồng đều, từ bản scan mờ nhòe, bị nghiêng cho đến các lỗi hình ảnh khác.
Quy trình vận hành tinh gọn và hiệu quả
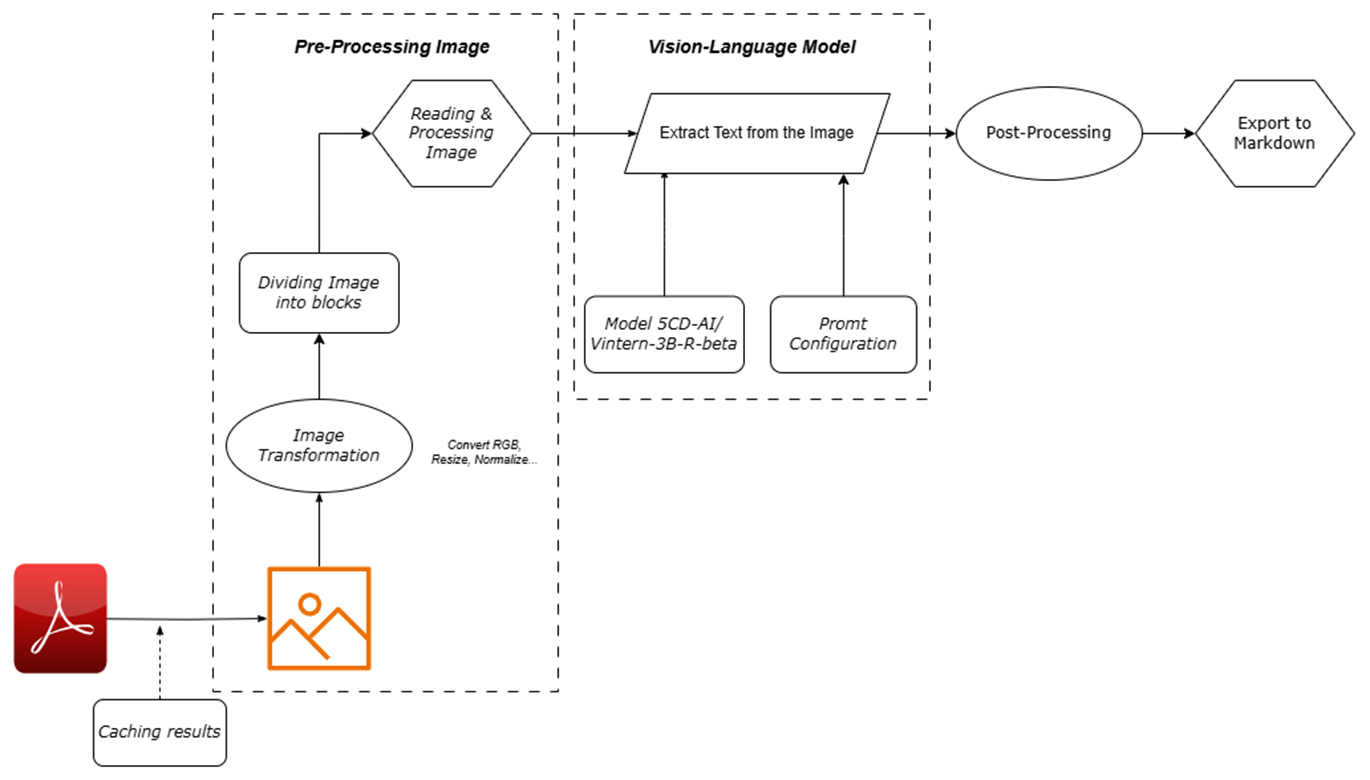
Quy trình xử lý của đồ án được xây dựng một cách khoa học và liền mạch, đảm bảo mọi tài liệu đều được xử lý một cách tối ưu:
- Tiếp nhận tài liệu: Hệ thống nhận tài liệu PDF, sau đó tự động chuyển đổi sang định dạng hình ảnh.
- Tiền xử lý thông minh: Áp dụng các kỹ thuật xử lý ảnh tiên tiến để cải thiện chất lượng, chuẩn hóa độ sáng/tương phản và tự động căn chỉnh tài liệu.
- Phân tích đa chiều: Tận dụng VLM để phân tích tài liệu, không chỉ nhận diện văn bản mà còn hiểu bố cục, ngữ cảnh, từ đó trích xuất thông tin một cách toàn diện.
- Tạo đầu ra có cấu trúc: Kết quả trích xuất được tự động chuyển thành định dạng Markdown, một định dạng có cấu trúc giúp bảo toàn bố cục và dễ dàng cho việc xử lý dữ liệu tự động.
Công nghệ tiên tiến nền tảng vững chắc
Để đảm bảo hệ thống hoạt động ổn định và hiệu quả, đồ án đã sử dụng những công nghệ nền tảng hiện đại nhất:
- Mô hình VLM chuyên biệt: Sử dụng Vintern-3B-R-beta, một mô hình được huấn luyện và tối ưu hóa đặc biệt cho tiếng Việt, mang lại hiệu suất trích xuất vượt trội.
- Quy trình phát triển hiện đại: Đồ án được phát triển với các thư viện và framework phổ biến như PyTorch, Transformers (Hugging Face) và Gradio, tuân thủ quy trình phát triển chuyên nghiệp.
- Môi trường triển khai linh hoạt: Hệ thống được triển khai trên nền tảng Google Colab, cho phép tiếp cận với các tài nguyên GPU mạnh mẽ cần thiết cho việc xử lý các mô hình AI.
“Text Extraction from PDF Documents using Vision-Language Models” không chỉ là một nghiên cứu học thuật mà còn mở ra một giải pháp thực tiễn được áp dụng vào nhiều lĩnh vực khác nhau trong thực tế. Đồ án thể hiện tiềm năng của học viên trong việc vận dụng công nghệ tiên tiến để giải quyết những vấn đề thiết thực trong đời sống và công việc.
Sự phát triển của một hệ thống trích xuất dữ liệu thông minh, hiệu quả và được tối ưu hóa cho tiếng Việt là một bước tiến quan trọng trong hành trình chuyển đổi số. Aptech hy vọng rằng đồ án sẽ là nền tảng để tiếp tục phát triển, đóng góp vào việc giải quyết những bài toán phức tạp, tiết kiệm thời gian, chi phí và nâng cao hiệu quả công việc một cách đáng kể.
| Có mặt tại Việt Nam từ năm 1999, Aptech đã và đang đào tạo biết bao thế hệ Lập trình viên tài năng cho ngành CNTT tại Việt Nam. Aptech là địa chỉ học tập uy tín cho các bạn trẻ Việt Nam, từ các bạn học sinh THPT, sinh viên cho đến người đi làm. Với phương pháp đào tạo từ cơ bản đến nâng cao, Aptech hiện đang đào tạo 2 chuyên ngành chính là Công nghệ phần mềm và Khoa học dữ liệu – Trí tuệ nhân tạo. Sau khi tốt nghiệp, các bạn có thể tự tin làm việc tại nhiều vị trí như: Kỹ sư Lập trình Web – App – Game – Software, chuyên viên Phân Tích Dữ liệu (Data Analyst), chuyên gia Khoa học dữ liệu (Data Scientist),… Xem thông tin chi tiết về chương trình tuyển sinh CNTT của Aptech tại đây: Chuyên ngành Khoa học dữ liệu – Trí tuệ nhân tạo: https://aptechvietnam.com.vn/khoahocdatascience-ai/ Các khóa học lập trình cho Sinh viên – người đi làm: https://aptechvietnam.com.vn/laptrinhsunghiep/ Chuyên ngành Công nghệ phần mềm dành cho các bạn THPT: https://aptechvietnam.com.vn/tuyensinh/ |

![Untitled-1-Thumnail [Recovered]-04](https://aptechvietnam.com.vn/wp-content/uploads/Untitled-1-Thumnail-Recovered-04.jpg)










